Understanding XML
Looking at the XML
This will be pretty long, but lets take a look at the XML from our previous request:
This XML contains all BGG's database information for the boardgame with the ID number 13. Just taking a quick glance through it, you can probably identify most of the tags. Tags like <yearpublished>, <minplayers>, <maxplayers>, <playingtime>, <minplaytime>, <maxplaytime>, and <age> are all pretty self-explanitory. The <name> tags all identify alternative names for the game, while the <name> tag with the primary="true" attribute is the game's primary name.
You should also see a <description>, an <image> which is the games featured image, <boardgamepublisher>, <boardgameartist>, and many more. The key thing to remember is that all of this information coincides with the information displayed on the game's entry page. If you take a look at Catan's entry page, the XML should make a lot more sense:

Doing more with XML
Ok, so now that we can understand the XML, how do we go about making use of it? For this, we're going to use a basic XML parser in our HTML page. If we put the following code into our original script, we should be able to get an HTML page that outputs the name of the game, taken from the XML:
When we render this page, you should see the following:

It's not much, but it's a start! So what's going on here? Lets look at this code a little more closely.
Our first script retrieved the XML and our second script starts by saving that XML in a variable called text. We create a new DOMParser() object called parser and use it to parse the text from our text variable and save the results in a new variable called xmlDoc. We then scan our HTML document for the object named catanName which is a <p> tag, and create a reference to it by the same name. Then we change the inner HTML of results by grabbing the 'value' attribute of the first <name> element in xmlDoc, which is "Catan".
A good thing to remember is the order in which things happen in this document. First the request is made, then the elements of the document are created, and finally those elements are filled by the data parsed from the XML. The second script needs to be at the bottom of the document, or else the script won't know where to place the data after it is parsed.
Lets try grabbing something different now. Lets grab the representative image for Catan. Take a look at the code below:
And lets see how that looks when the page renders:
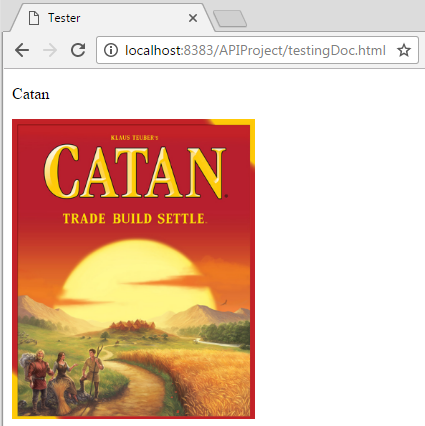
Just as before, we've added a new element in the HTML for an image to be placed, and given it an ID value of catanImg. Then we create a reference to that element with the same name, and fill in the src attribute of that element with a value take from the parsed XML. To get that value, we just need to find the element with the tag name of "image". Note that the value we are returned doesn't contain the "https:" prefix so we need to add that in. Not too bad, huh?