I recently was given the task of gathering data from several xml files that were automatically generated based on search queries. After going through the first few files, I realized that my current process was quite inefficient. I started by clicking the link to the xml data, which would then render inside of Google Chrome. It looked something like this (although the actual xml files were much longer):
 I would then use
I would then use ctrl+f to look for the piece of data I needed. This was a painfully slow process, as I had to find a lot of data, and often the xml nodes had the same names but in different places. This lead to a lot of wasted time double and triple-checking that the data I was looking at was the correct data. I figured there had to be a better way.
It was about this time that I learned about XPath, which I figured could do a lot to speed up the process. Unfortunately, Chrome’s default xml viewer doesn’t support XPath, so I figured there must be a plugin out there that does. I started by trying out the XV XML Viewer plugin, but it seemed to still be in slow development and the XPath support was really lacking. In addition, it made it difficult to copy+paste XML as that feature had been disabled in a recent release. I also learned about the excellent plugin ChroPath which supports XPath, but really only for DOM manipulation. It didn’t work very well on the XML pages rendered in Chrome.
After spending a lot of time trying out various Chrome plugins, I remembered that VS Code has XPath functionality built right into it. Now all I needed to do was open the file in Chrome, copy+paste it into VS Code and I could use XPath to my heart’s delight… except that when you copy+paste from Chrome, it includes all of the HTML Chrome adds to display the XML, and you have to spend extra time removing it all. Ugh.
I tried to see if there was a way to get Chrome to display XML as plain text, instead of rendering it inside an HTML document. I couldn’t find one. The only alternative was to right-clicking the document after it loaded and save it to my desktop. This annoyed me because I would rather Chrome not open the file at all and just download it straight-away. After lots of research online, I finally figured out how to enable this functionality.
First, I needed to intercept the HTTP response from the server change the variables in the header so Chrome wouldn’t know that it was receiving an XML document. I also had to inform Chrome that this file should be downloaded, and that Chrome shouldn’t attempt to open it. To do this, I downloaded the plugin ModHeader and gave it the following settings: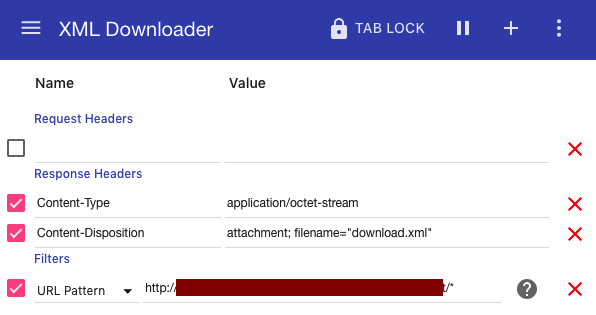 Now whenever I encountered a file with a Content-Type of xml on that specific domain, ModHeader would intercept its response header and change it to
Now whenever I encountered a file with a Content-Type of xml on that specific domain, ModHeader would intercept its response header and change it to application/octet-stream which is sort of just a generic type. It would then label the file as an attachment which means it is to be downloaded, and give it a file name. Voilà! Files automatically downloaded!
Next I told Chrome to just open .xml files automatically with my system’s default program, and they show up instantly in VS Code! I can now access XML files and run XPath searches on them instantly and am able to save a ton of time. Good stuff.
Hi, very interesting! It is possible to download different files (named differently) from different url?
I tried creating a new profile but can be activated only 1 profile at a time